
Introduction
LEA is a 128-bit block cipher with support for 128, 192 and 256-bit keys published in 2014. It was designed by Deukjo Hong, Jung-Keun Lee, Dong-Chan Kim, Daesung Kwon, Kwon Ho Ryu, and Dong-Geon Lee. The only operations used for encryption and the key schedule are 32-bit Addition, eXclusive OR and Rotation (ARX structure): the designers state “the usage of 32-bit and 64-bit processors will grow rapidly compared to 8-bit and 16-bit ones”. Today I’ll just focus on an implementation using 128-bit keys referred to as LEA-128. This just about fits onto the 32-bit x86 architecture. The 256-bit version requires additional registers and is probably better suited for 64-bit mode.
Key Schedule
During generation of subkeys, a number of predefined constants are used.


![\delta[0] = 0xc3efe9db, \quad \delta[1] = 0x44626b02,](https://s0.wp.com/latex.php?latex=%5Cdelta%5B0%5D+%3D+0xc3efe9db%2C+%5Cquad+%5Cdelta%5B1%5D+%3D+0x44626b02%2C+&bg=ffffff&fg=333333&s=0&c=20201002)
![\delta[2] = 0x79e27c8a, \quad \delta[3] = 0x78df30ec,](https://s0.wp.com/latex.php?latex=%5Cdelta%5B2%5D+%3D+0x79e27c8a%2C+%5Cquad+%5Cdelta%5B3%5D+%3D+0x78df30ec%2C+&bg=ffffff&fg=333333&s=0&c=20201002)
![\delta[4] = 0x715ea49e, \quad \delta[5] = 0xc785da0a,](https://s0.wp.com/latex.php?latex=%5Cdelta%5B4%5D+%3D+0x715ea49e%2C+%5Cquad+%5Cdelta%5B5%5D+%3D+0xc785da0a%2C+&bg=ffffff&fg=333333&s=0&c=20201002)
![\delta[6] = 0xe04ef22a, \quad \delta[7] = 0xe5c40957.](https://s0.wp.com/latex.php?latex=%5Cdelta%5B6%5D+%3D+0xe04ef22a%2C+%5Cquad+%5Cdelta%5B7%5D+%3D+0xe5c40957.+&bg=ffffff&fg=333333&s=0&c=20201002)

You can obtain the values using a tool like speedcrunch.

There are 3 different key schedule functions but I only focus on the 128-bit variant for now.
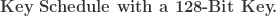
![\text{Let } K = (K[0], K[1], K[2], K[3]) \text{ be a 128-bit key. We set } T[i] = K[i]\: for \: 0\leq 4. \text{ Round key} RK_i = (RK_i[0], RK_i[1],\dots , RK_i[5])\: for\: 0\leq i < 24 \text{ are produced through the following relations:}](https://s0.wp.com/latex.php?latex=%5Ctext%7BLet+%7D+K+%3D+%28K%5B0%5D%2C+K%5B1%5D%2C+K%5B2%5D%2C+K%5B3%5D%29+%5Ctext%7B+be+a+128-bit+key.+We+set+%7D+T%5Bi%5D+%3D+K%5Bi%5D%5C%3A+for+%5C%3A+0%5Cleq+4.+++%5Ctext%7B+Round+key%7D+RK_i+%3D+%28RK_i%5B0%5D%2C+RK_i%5B1%5D%2C%5Cdots+%2C+RK_i%5B5%5D%29%5C%3A+for%5C%3A+0%5Cleq+i+%3C+24+%5Ctext%7B+are+produced+through+the+following+relations%3A%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![T[0]\leftarrow ROL_1(T[0]\oplus ROL_i(\delta[i\:mod\: 4])),\\ T[1]\leftarrow ROL_3(T[1]\oplus ROL_{i+1}(\delta[i\:mod\: 4])),\\ T[2]\leftarrow ROL_6(T[2]\oplus ROL_{i+2}(\delta[i\:mod\: 4])),\\ T[3]\leftarrow ROL_{11}(T[3]\oplus ROL_{i+3}(\delta[i\:mod\: 4])),\\ RK_i\leftarrow (T[0], T[1], T[2], T[3], T[1]).](https://s0.wp.com/latex.php?latex=T%5B0%5D%5Cleftarrow+ROL_1%28T%5B0%5D%5Coplus+ROL_i%28%5Cdelta%5Bi%5C%3Amod%5C%3A+4%5D%29%29%2C%5C%5C++T%5B1%5D%5Cleftarrow+ROL_3%28T%5B1%5D%5Coplus+ROL_%7Bi%2B1%7D%28%5Cdelta%5Bi%5C%3Amod%5C%3A+4%5D%29%29%2C%5C%5C++T%5B2%5D%5Cleftarrow+ROL_6%28T%5B2%5D%5Coplus+ROL_%7Bi%2B2%7D%28%5Cdelta%5Bi%5C%3Amod%5C%3A+4%5D%29%29%2C%5C%5C++T%5B3%5D%5Cleftarrow+ROL_%7B11%7D%28T%5B3%5D%5Coplus+ROL_%7Bi%2B3%7D%28%5Cdelta%5Bi%5C%3Amod%5C%3A+4%5D%29%29%2C%5C%5C++RK_i%5Cleftarrow+%28T%5B0%5D%2C+T%5B1%5D%2C+T%5B2%5D%2C+T%5B3%5D%2C+T%5B1%5D%29.++&bg=ffffff&fg=333333&s=0&c=20201002)
Compact code
The following function combines encryption and key scheduling. It will encrypt 128-bits of data using a 128-bit master key mk. I’d suggest using this with counter (CTR) mode.
#define R(v,n)(((v)>>(n))|((v)<<(32-(n)))) typedef unsigned int W; void lea128(void*mk,void*p) { W r,t,*x=p,*k=mk; W c[4]= {0xc3efe9db,0x88c4d604, 0xe789f229,0xc6f98763}; for(r=0;r<24;r++){ t=c[r%4]; c[r%4]=R(t,28); *k=R(*k+t,31); k[1]=R(k[1]+R(t,31),29); k[2]=R(k[2]+R(t,30),26); k[3]=R(k[3]+R(t,29),21); t=*x; *x=R((*x^*k)+(x[1]^k[1]),23); x[1]=R((x[1]^k[2])+(x[2]^k[1]),5); x[2]=R((x[2]^k[3])+(x[3]^k[1]),3); x[3]=t; } }
x86 assembly
You might notice the constants are different from C source. For whatever reason, the last 3 are rotated a number of bits left before entering the encryption loop. Obviously a compiler will be smart enough to see this and automatically optimize, but for assembly code, we must rotate them manually. They’re stored on the stack using PUSHAD. EDI, ESI, EBP and ESP are used for TD array. ESP has to be initialized after the PUSHAD for obvious reasons. We don’t want to cause an exception.
; ----------------------------------------------- ; LEA-128/128 Block Cipher in x86 assembly (Encryption only) ; ; size: 136 bytes ; ; global calls use cdecl convention ; ; ----------------------------------------------- %ifndef BIN global lea128 global _lea128 %endif bits 32 struc pushad_t _edi resd 1 _esi resd 1 _ebp resd 1 _esp resd 1 _ebx resd 1 _edx resd 1 _ecx resd 1 _eax resd 1 .size: endstruc ; plain text %define w0 dword[esi+4*0] %define w1 dword[esi+4*1] %define w2 dword[esi+4*2] %define w3 dword[esi+4*3] %define w4 ecx ; key %define w5 ebx %define w6 edx %define w7 edi %define w8 ebp %define LEA128_RNDS 24 lea128: _lea128: pushad ; initialize 4 constants mov edi, 0xc3efe9db ; c0 mov esi, 0x88c4d604 ; c1 mov ebp, 0xe789f229 ; c2 pushad mov dword[esp+_esp], 0xc6f98763 ; c3 mov esi, [esp+64+4] ; esi = key ; load key lodsd xchg eax, w5 lodsd xchg eax, w6 lodsd xchg eax, w7 lodsd xchg eax, w8 mov esi, [esp+64+8] ; esi = data xor eax, eax ; i = 0 lea_l0: push eax ; t = c[r%4]; and al, 3 mov w4, [esp+eax*4+4] ; c[r%4] = R(t, 28); ror dword[esp+eax*4+4], 28 ; ************************************** ; create sub key ; ************************************** ; k[0] = R(k[0] + t, 31); add w5, w4 rol w5, 1 ; k[1] = R(k[1] + R(t, 31), 29); rol w4, 1 add w6, w4 ror w6, 29 ; k[2] = R(k[2] + R(t, 30), 26); rol w4, 1 add w7, w4 ror w7, 26 ; k[3] = R(k[3] + R(t, 29), 21); rol w4, 1 add w8, w4 ror w8, 21 ; ************************************** ; encrypt block ; ************************************** ; t = x[0]; push w0 ; x[0] = R((x[0] ^ k[0]) + (x[1] ^ k[1]), 23); mov w4, w1 xor w4, w6 xor w0, w5 add w0, w4 ror w0, 23 ; x[1] = R((x[1] ^ k[2]) + (x[2] ^ k[1]), 5); mov w4, w2 xor w4, w6 xor w1, w7 add w1, w4 ror w1, 5 ; x[2] = R((x[2] ^ k[3]) + (x[3] ^ k[1]), 3); mov w4, w3 xor w4, w6 xor w2, w8 add w2, w4 ror w2, 3 ; x[3] = t; pop w3 pop eax ; i++; inc eax ; i<LEA128_RNDS cmp al, LEA128_RNDS jnz lea_l0 popad popad ret
ARM64 assembly
// LEA-128/128 in ARM64 assembly // 224 bytes .arch armv8-a // include the MOVL macro .include "../../include.inc" .text .global lea128 lea128: mov x11, x0 mov x12, x1 // allocate 16 bytes sub sp, sp, 4*4 // load immediate values movl w0, 0xc3efe9db movl w1, 0x88c4d604 movl w2, 0xe789f229 movl w3, 0xc6f98763 // store on stack str w0, [sp ] str w1, [sp, 4] str w2, [sp, 8] str w3, [sp, 12] // for(r=0;r<24;r++) { mov w8, wzr // load 128-bit key ldp w4, w5, [x11] ldp w6, w7, [x11, 8] // load 128-bit plaintext ldp w0, w1, [x12] ldp w2, w3, [x12, 8] L0: // t=c[r%4]; and w9, w8, 3 ldr w10, [sp, x9, lsl 2] // c[r%4]=R(t,28); mov w11, w10, ror 28 str w11, [sp, x9, lsl 2] // k[0]=R(k[0]+t,31); add w4, w4, w10 ror w4, w4, 31 // k[1]=R(k[1]+R(t,31),29); ror w11, w10, 31 add w5, w5, w11 ror w5, w5, 29 // k[2]=R(k[2]+R(t,30),26); ror w11, w10, 30 add w6, w6, w11 ror w6, w6, 26 // k[3]=R(k[3]+R(t,29),21); ror w11, w10, 29 add w7, w7, w11 ror w7, w7, 21 // t=x[0]; mov w10, w0 // w[0]=R((w[0]^k[0])+(w[1]^k[1]),23); eor w0, w0, w4 eor w9, w1, w5 add w0, w0, w9 ror w0, w0, 23 // w[1]=R((w[1]^k[2])+(w[2]^k[1]),5); eor w1, w1, w6 eor w9, w2, w5 add w1, w1, w9 ror w1, w1, 5 // w[2]=R((w[2]^k[3])+(w[3]^k[1]),3); eor w2, w2, w7 eor w3, w3, w5 add w2, w2, w3 ror w2, w2, 3 // w[3]=t; mov w3, w10 // r++ add w8, w8, 1 // r < 24 cmp w8, 24 bne L0 // save 128-bit ciphertext stp w0, w1, [x12] stp w2, w3, [x12, 8] add sp, sp, 4*4 ret
Thanks to 0x4d_ for submitting 

Pingback: Shellcode: Encryption Algorithms in ARM Assembly | modexp