
Introduction
CHAM: A Family of Lightweight Block Ciphers for Resource-Constrained Devices was published in December 2017 at the 20th Annual International Conference on Information Security and Cryptology held in South Korea. CHAM consists of three ciphers, CHAM-64/128 for 16-bit architectures, CHAM-128/128 and CHAM-128/256 for 32-bit architectures. This post will only focus on CHAM-128/128 that operates on four branches of 32 bits each. The only operations used are 32-bit modular addition, rotation and exclusive-OR (ARX). The design of CHAM draws inspiration from the SPECK and SIMON block ciphers published by the NSA.
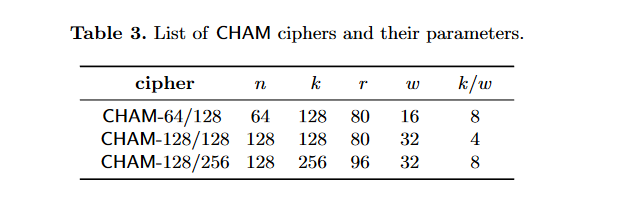
The following are parameters for all three variants. N is the block length, K is the key length, R is the number of rounds, W is the width of a word and K/W is the number of words per key.
Key schedule
Eight round keys are generated from the 128-bit master key. Each round key is 32-bits in length.
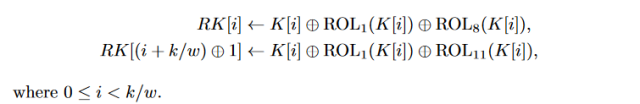
void cham128_setkey(void *in, void *out) { int i; uint32_t *k=(uint32_t*)in; uint32_t *rk=(uint32_t*)out; for (i=0; i<KW; i++) { rk[i] = k[i] ^ ROTL32(k[i], 1) ^ ROTL32(k[i], 8); rk[(i + KW) ^ 1] = k[i] ^ ROTL32(k[i], 1) ^ ROTL32(k[i], 11); } }
x86 assembly
%define K 128 ; key length %define N 128 ; block length %define R 80 ; number of rounds %define W 32 ; word length %define KW K/W ; number of words per key cham128_setkeyx: _cham128_setkeyx: pushad mov esi, [esp+32+4] ; k = in mov edi, [esp+32+8] ; rk = out xor eax, eax ; i = 0 sk_l0: mov ebx, [esi+eax*4] ; ebx = k[i] mov ecx, ebx ; ecx = k[i] mov edx, ebx ; edx = k[i] rol ebx, 1 ; ROTL32(k[i], 1) rol ecx, 8 ; ROTL32(k[i], 8) xor edx, ebx ; k[i] ^ ROTL32(k[i], 1) xor edx, ecx mov [edi+eax*4], edx ; rk[i] = edx xor edx, ecx ; reset edx rol ecx, 3 ; k[i] ^ ROTL32(k[i], 11) xor edx, ecx lea ebx, [eax+KW] xor ebx, 1 mov [edi+ebx*4], edx ; rk[(i + KW) ^ 1] = edx inc al cmp al, KW jnz sk_l0 popad ret
Encryption
There are 80 rounds in total; this is significantly more than the 34 used for SPECK-128/128.

void cham128_encrypt(void *keys, void *data) { int i; uint32_t x0, x1, x2, x3; uint32_t t; uint32_t *rk=(uint32_t*)keys; uint32_t *x=(uint32_t*)data; x0 = x[0]; x1 = x[1]; x2 = x[2]; x3 = x[3]; for (i=0; i<R; i++) { if ((i & 1) == 0) { x0 = ROTL32((x0 ^ i) + (ROTL32(x1, 1) ^ rk[i & 7]), 8); } else { x0 = ROTL32((x0 ^ i) + (ROTL32(x1, 8) ^ rk[i & 7]), 1); } XCHG(x0, x1); XCHG(x1, x2); XCHG(x2, x3); } x[0] = x0; x[1] = x1; x[2] = x2; x[3] = x3; }
Compact code
#define R(v,n)(((v)>>(n))|((v)<<(32-(n)))) #define F(n)for(i=0;i<n;i++) typedef unsigned int W; void cham(void*mk,void*p){ W rk[8],*w=p,*k=mk,i,t; F(4) t=k[i]^R(k[i],31), rk[i]=t^R(k[i],24), rk[(i+4)^1]=t^R(k[i],21); F(80) t=w[3],w[0]^=i,w[3]=rk[i&7], w[3]=w[0]+(w[3]^R(w[1],(i&1)?24:31)), w[3]=R(w[3],(i&1)?31:24), w[0]=w[1],w[1]=w[2],w[2]=t; }
x86 assembly
Only the encryption here, since if you were to implement with CTR mode, decryption isn’t necessary.
; ----------------------------------------------- ; CHAM-128/128 block cipher in x86 assembly ; ; size: 124 bytes ; ; global calls use cdecl convention ; ; ----------------------------------------------- bits 32 %ifndef BIN global cham global _cham %endif %define K 128 ; key length %define N 128 ; block length %define R 80 ; number of rounds %define W 32 ; word length %define KW K/W ; number of words per key %define x0 ebp %define x1 ebx %define x2 edx %define x3 esi %define rk edi cham: _cham: pushad mov esi, [esp+32+4] ; k = key mov ebp, [esp+32+8] ; x = data pushad ; allocate 2*KW mov edi, esp ; edi = rk xor eax, eax ; i = 0 sk_l0: mov ebx, [esi+eax*4] ; ebx = k[i] mov ecx, ebx ; ecx = k[i] mov edx, ebx ; edx = k[i] rol ebx, 1 ; ROTL32(k[i], 1) rol ecx, 8 ; ROTL32(k[i], 8) xor edx, ebx ; k[i] ^ ROTL32(k[i], 1) xor edx, ecx mov [edi+eax*4], edx ; rk[i] = edx xor edx, ecx ; reset edx rol ecx, 3 ; k[i] ^ ROTL32(k[i], 11) xor edx, ecx lea ebx, [eax+KW] xor ebx, 1 mov [edi+ebx*4], edx ; rk[(i + KW) ^ 1] = edx inc eax cmp al, KW jnz sk_l0 xchg esi, ebp push esi lodsd xchg eax, x0 lodsd xchg eax, x1 lodsd xchg eax, x2 lodsd xchg eax, x3 xor eax, eax ; i = 0 ; initialize sub keys enc_l0: mov edi, ebp ; k = keys jmp enc_lx enc_l1: test al, 7 ; i & 7 jz enc_l0 enc_lx: push eax ; save i mov cx, 0x0108 test al, 1 ; if ((i & 1)==0) jnz enc_l2 xchg cl, ch enc_l2: xor x0, eax ; x0 ^= i mov eax, x1 rol eax, cl ; xor eax, [edi] ; ROTL32(x1, r0) ^ *rk++ scasd add x0, eax xchg cl, ch rol x0, cl xchg x0, x1 ; XCHG(x0, x1); xchg x1, x2 ; XCHG(x1, x2); xchg x2, x3 ; XCHG(x2, x3); pop eax ; restore i inc eax ; i++ cmp al, R ; i<R jnz enc_l1 pop edi xchg eax, x0 stosd ; x[0] = x0; xchg eax, x1 stosd ; x[1] = x1; xchg eax, x2 stosd ; x[2] = x2; xchg eax, x3 stosd ; x[3] = x3; popad ret
ARM / AArch32 assembly
.arm .arch armv7-a .text .global cham k .req r0 x .req r1 // data x0 .req r0 x1 .req r2 x2 .req r3 x3 .req r4 // round keys rk .req sp k0 .req r6 k1 .req r7 k2 .req r8 i .req r10 cham: // save registers push {r0-r12,lr} // allocate memory for round keys sub sp, #32 // derive round keys from 128-bit key mov i, #0 // i = 0 cham_init: ldr k0, [k, i, lsl #2] // k0 = k[i]; ror k1, k0, #31 // k1 = ROTR32(k0, 31); ror k2, k0, #24 // k2 = ROTR32(k0, 24); eor k0, k1 // k0^= k1; eor k1, k0, k2 // rk[i] = k0 ^ k2; str k1, [rk, i, lsl #2] eor k0, k2, ror #29 // k0 ^= ROTR32(k2, 29); add k1, i, #4 // k1 = (i+KW) eor k1, #1 // k1 = (i+KW) ^ 1 str k0, [rk, k1, lsl #2] // rk[(i+KW)^1] = k0; add i, #1 // i++ cmp i, #4 // i<KW bne cham_init // // load 128-bit plain text ldm x, {x0, x1, x2, x3} // perform encryption mov i, #0 // i = 0 cham_enc: mov k0, x3 eor x0, i // x0 ^= i tst i, #1 // if (i & 1) // x3 = rk[i & 7]; and k1, i, #7 // k1 = i & 7; ldr x3, [rk, k1, lsl #2] // x3 = rk[i & 7]; // execution depends on (i % 2) // x3 ^= (i & 1) ? ROTR32(x1, 24) : ROTR32(x1, 31); eorne x3, x1, ror #24 // eoreq x3, x1, ror #31 // add x3, x0 // x3 += x0; // x3 = (i & 1) ? ROTR32(x3, 31) : ROTR32(x3, 24); rorne x3, #31 // x3 = ROTR32(x3, 31); roreq x3, #24 // x3 = ROTR32(x3, 24); // swap mov x0, x1 // x0 = x1; mov x1, x2 // x1 = x2; mov x2, k0 // x2 = k0; add i, #1 // i++; cmp i, #80 // i<R bne cham_enc // // save 128-bit cipher text stm x, {x0, x1, x2, x3} // x[0] = x0; x[1] = x1; // x[2] = x2; x[3] = x3; // release memory for round keys add sp, #32 // restore registers pop {r0-r12, pc}
ARM64 / AArch64 assembly
// CHAM 128/128 in ARM64 assembly // 160 bytes .arch armv8-a .text .global cham // cham(void*mk,void*p); cham: sub sp, sp, 32 mov w2, wzr mov x8, x1 L0: // t=k[i]^R(k[i],31), ldr w5, [x0, x2, lsl 2] eor w6, w5, w5, ror 31 // rk[i]=t^R(k[i],24), eor w7, w6, w5, ror 24 str w7, [sp, x2, lsl 2] // rk[(i+4)^1]=t^R(k[i],21); eor w7, w6, w5, ror 21 add w5, w2, 4 eor w5, w5, 1 str w7, [sp, x5, lsl 2] // i++ add w2, w2, 1 // i < 4 cmp w2, 4 bne L0 ldp w0, w1, [x8] ldp w2, w3, [x8, 8] // i = 0 mov w4, wzr L1: tst w4, 1 // t=w[3],w[0]^=i,w[3]=rk[i%8], mov w5, w3 eor w0, w0, w4 and w6, w4, 7 ldr w3, [sp, x6, lsl 2] // w[3]^=R(w[1],(i & 1) ? 24 : 31), mov w6, w1, ror 24 mov w7, w1, ror 31 csel w6, w6, w7, ne eor w3, w3, w6 // w[3]+=w[0], add w3, w3, w0 // w[3]=R(w[3],(i & 1) ? 31 : 24), mov w6, w3, ror 31 mov w7, w3, ror 24 csel w3, w6, w7, ne // w[0]=w[1],w[1]=w[2],w[2]=t; mov w0, w1 mov w1, w2 mov w2, w5 // i++ add w4, w4, 1 // i < 80 cmp w4, 80 bne L1 stp w0, w1, [x8] stp w2, w3, [x8, 8] add sp, sp, 32 ret

Pingback: Shellcode: Encryption Algorithms in ARM Assembly | modexp